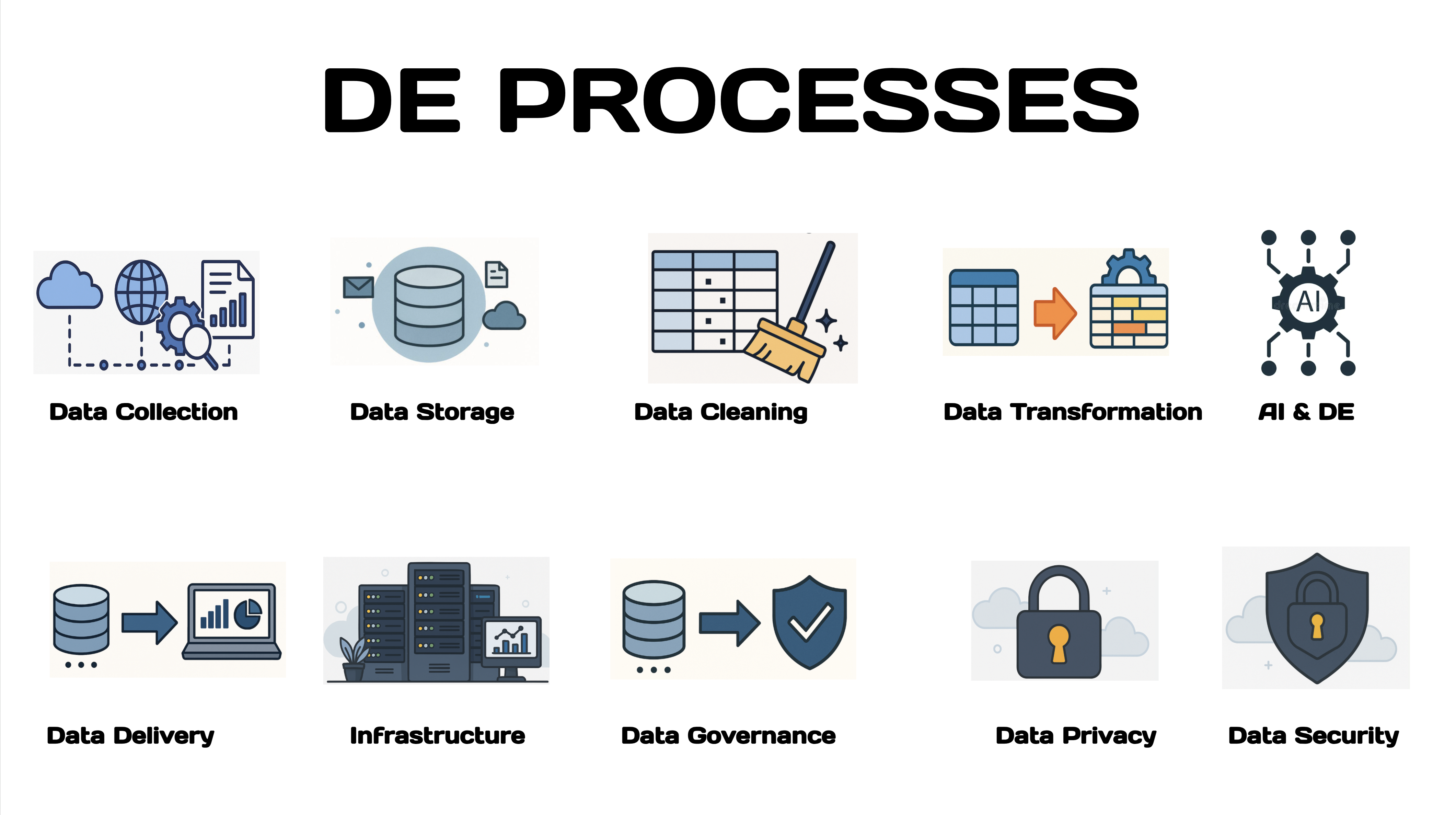
Data engineering processes involve the design, construction, and maintenance of systems that handle the lifecycle of data, from its collection and storage to its transformation and delivery for analysis and decision-making.
These processes are crucial for ensuring data is accessible, reliable, and usable by other teams within an organization, like data scientists and analysts.
In essence, data engineering processes are the foundation for leveraging data within an organization. By building robust and efficient data systems, data engineers enable other teams to derive valuable insights and make data-driven decisions.
Source: Gemini AI Overview
OnAir Post: DE Processes Overview