Summary
Data engineering plays a crucial role in AI and machine learning by providing the infrastructure and systems needed to manage and process the vast amounts of data that these technologies rely on. Data engineers build and maintain the pipelines, databases, and data architectures that enable AI and ML models to learn and make predictions.
In essence, data engineering provides the raw materials (data) and the tools (pipelines, infrastructure) for AI and ML to function effectively. AI and ML, in turn, are being integrated into data engineering processes to improve efficiency, accuracy, and the overall ability to extract value from data.
Source: Gemini AI Overview
OnAir Post: AI and Machine Learning
About
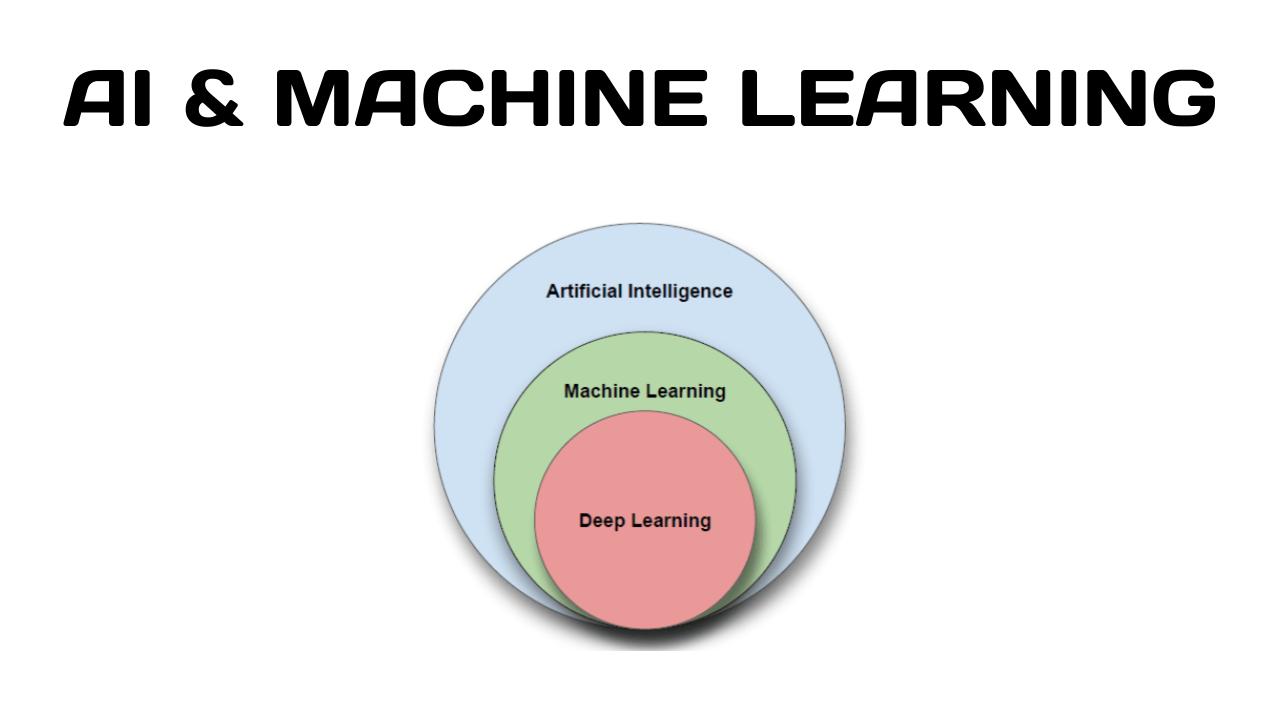
Artificial Intelligence
AI, or Artificial Intelligence, refers to the ability of computer systems to perform tasks that typically require human intelligence. This includes learning, problem-solving, decision-making, and perception. Essentially, it’s about creating machines that can think and act like humans.
Source: Google Gemini Overview
Machine Learning
Machine learning (ML) is a subset of artificial intelligence that focuses on enabling systems to learn from data and improve their performance on specific tasks without explicit programming. Essentially, instead of being hard-coded with rules, machine learning algorithms analyze data to identify patterns and make predictions or decisions.
Core Concepts:
- Learning from Data:ML algorithms learn from data, identifying patterns and relationships within it. This learning process allows them to make predictions or decisions on new, unseen data.
- No Explicit Programming:Unlike traditional programming where every step is explicitly defined, ML algorithms are designed to learn from data and improve their performance over time with more data.
- Algorithms and Models:ML relies on algorithms, which are sets of instructions, to analyze data and build models. These models are then used for predictions or decisions.
- Types of ML:There are various types of machine learning, including supervised, unsupervised, and reinforcement learning, each with its own approach to learning from data.
- Supervised Learning: Uses labeled data to train algorithms to predict or classify outcomes.
- Unsupervised Learning: Deals with unlabeled data to discover patterns and relationships within the data.
- Reinforcement Learning: Trains agents to make decisions in an environment through trial and error, receiving rewards for good actions.
Source: Google Gemini Overview
Relationship with Data Engineering
- Data Engineering as the Foundation:High-quality, well-structured data is essential for building robust AI and ML models. Data engineers ensure this foundation is in place by building and maintaining the data pipelines and infrastructure.
- AI/ML Enhancing Data Engineering:AI and ML techniques are increasingly being used within data engineering processes to automate tasks, improve data quality, and enhance data analysis capabilities.
- AI-powered data quality monitoring: Identifying and correcting data errors in real-time.
- Automated data pipeline optimization: Using machine learning to improve the efficiency of data processing workflows.
- AI-driven data discovery and access: Helping users find and access the data they need more easily.
Source: Google Gemini Overview
Challenges
Data engineering for AI and machine learning presents several key challenges, including managing the volume, variety, and velocity of data (the 3Vs of big data), ensuring data quality and consistency, handling unstructured data, maintaining data privacy and security, and integrating diverse data sources. Additionally, there are concerns about data bias, the scalability and performance of AI models, and the ethical implications of AI decision-making.
Addressing these challenges requires a combination of technical expertise, strong data governance practices, and a commitment to ethical AI development.
Initial Source for content: Gemini AI Overview
[Enter your questions, feedback & content (e.g. blog posts, Google Slide or Word docs, YouTube videos) on the key issues and challenges related to this post in the “Comment” section below. Post curators will review your comments & content and decide where and how to include it in this section.]
1. Data Quality and Availability
- Data Volume, Variety, and VelocityBig data introduces the challenge of handling massive datasets with diverse structures and high update frequencies.
- Data Cleaning and TransformationReal-world data is often messy, requiring significant effort to clean, transform, and prepare it for machine learning algorithms.
- Handling Missing DataMissing data points can significantly impact model accuracy and require careful handling through imputation or other techniques.
- Dealing with Noise and OutliersData noise and outliers can negatively affect model performance, necessitating strategies for noise reduction and outlier detection, according to Number Analytics and Trantor.
- Data DriftChanges in data distributions over time (data drift) can lead to model degradation, requiring continuous monitoring and adaptation.
2. Data Privacy and Security
- Data Encryption and Access ControlImplementing encryption, access controls, and monitoring systems is crucial for protecting data privacy and preventing unauthorized access.
- Ethical ConsiderationsAI systems must be designed and deployed responsibly, considering potential biases and unintended consequences.
3. Scalability and Performance
- Handling Large DatasetsAI models often require vast amounts of data, necessitating scalable infrastructure and efficient data processing pipelines.
- Real-time ProcessingMany AI applications require real-time or near real-time data processing, demanding efficient streaming data pipelines.
- Model DeploymentDeploying and scaling machine learning models into production environments can be complex, requiring robust infrastructure and monitoring systems.
4. Model Bias and Fairness
- Data BiasAI models can perpetuate and amplify existing societal biases if trained on biased datasets.
- Fairness in Decision-MakingData engineers need to be mindful of the potential for unfair outcomes in AI-driven decision-making processes and strive for fairness and transparency, says DZone.
5. Integration and Orchestration
- Data Source IntegrationAI systems often rely on data from diverse sources, requiring robust integration and data management capabilities.
- Pipeline OrchestrationManaging the flow of data through complex pipelines involving data ingestion, cleaning, feature engineering, model training, and deployment is essential.
6. Model Development and Training
- Feature EngineeringSelecting and transforming relevant features from raw data is crucial for model performance, requiring domain expertise and creativity.
- OverfittingModels can become too specialized to the training data (overfitting), requiring techniques to generalize well to unseen data.
- Training/Serving SkewDiscrepancies between the data used for training and the data used for serving predictions can impact model accuracy, according to Tecton.
Research
Research in Data Engineering for AI and Machine Learning focuses on developing and optimizing the infrastructure and processes needed to support AI and ML model development and deployment. This includes areas like data collection, cleaning, transformation, feature engineering, and model deployment pipelines. It also involves using AI and ML techniques to enhance data engineering tasks themselves, such as automating data quality checks or optimizing data pipelines.
In essence, research in Data Engineering for AI and ML aims to make the process of building and deploying AI/ML models more efficient, reliable, and scalable. It leverages AI/ML techniques to improve the data engineering process itself, creating a virtuous cycle of innovation.
Initial Source for content: Gemini AI Overview
[Enter your questions, feedback & content (e.g. blog posts, Google Slide or Word docs, YouTube videos) on innovative research related to this post in the “Comment” section below. Post curators will review your comments & content and decide where and how to include it in this section.]
1. Foundational Research in Data Engineering for AI/ML
- Research focuses on building efficient and scalable data pipelines that can handle the large volumes and velocity of data required for AI/ML models.
- Ensuring data quality is crucial for reliable AI/ML models. Research explores techniques for data validation, anomaly detection, and data cleaning to improve data accuracy and consistency.
- Research investigates methods for creating effective features from raw data that can improve model performance.
- Research focuses on building robust and efficient systems for deploying and managing AI/ML models in production, including monitoring and maintenance.
2. AI/ML Techniques in Data Engineering
- AI/ML algorithms can automate many data engineering tasks, such as data quality checks, data cleaning, and data transformation.
- Machine learning models can be used to automatically detect anomalies in data, which can help identify errors or unusual patterns.
- Data engineers can use AI/ML to build predictive models for tasks like forecasting, anomaly detection, and data quality assessment.
- NLP techniques can be used to extract information from unstructured data sources like text documents, enabling data engineers to process and analyze this data more effectively.
3. Specific Research Areas
- Research explores automating the process of building and deploying machine learning models, including tasks like feature selection, model selection, and hyperparameter tuning.
- Research focuses on developing tools and techniques for managing different versions of data, which is crucial for reproducibility and collaboration in AI/ML projects.
- Research explores ways to build intelligent data catalogs that can help users discover and understand data assets, including metadata management and data lineage tracking.
- Research investigates how to implement data governance policies and controls to ensure data privacy, security, and compliance.
- Research explores the use of vector databases for storing and querying data in a way that is optimized for AI/ML models.
- Research focuses on building low-latency data pipelines for processing data in real-time, enabling applications that require immediate responses.
Projects
Recent and future projects in data engineering are heavily influenced by AI and machine learning, focusing on automation, enhanced data pipelines, and improved insights. These projects include AI-powered data quality management, automated ETL processes, and the development of self-healing data systems. Furthermore, AI is being integrated into data visualization, governance, and even the design and management of data pipelines themselves.
Initial Source for content: Gemini AI Overview
[Enter your questions, feedback & content (e.g. blog posts, Google Slide or Word docs, YouTube videos) on current and future projects implementing solutions to this post challenges in the “Comment” section below. Post curators will review your comments & content and decide where and how to include it in this section.]
1. AI-Powered Data Quality and Governance
- Automated Data Quality ChecksAI algorithms can be used to automatically detect and correct data inconsistencies, anomalies, and errors in real-time, improving data quality and reliability.
- Automated ETL ProcessesAI can automate the extraction, transformation, and loading (ETL) of data, making data pipelines more efficient and reducing manual effort.
- AI-Driven Data GovernanceAI can help enforce data governance policies, track data lineage, and ensure compliance with regulations like GDPR and CCPA.
- Real-time Data Drift DetectionAI can monitor data streams for changes in statistical properties (data drift) and trigger alerts when data quality is compromised.
2. AI in Data Pipelines and Orchestration
- Automated Pipeline DesignAI can analyze data patterns and suggest optimal pipeline configurations for specific tasks, improving efficiency and performance.
- Context-Aware SchedulingAI-powered orchestration platforms can dynamically adjust pipeline execution based on real-time data characteristics and resource availability.
- Anomaly Detection in PipelinesAI can identify unusual patterns in pipeline execution, flagging potential bottlenecks or errors for faster troubleshooting.
3. AI in Data Visualization and Insights
- AI-Enhanced Data VisualizationAI can automatically generate insights from complex datasets and present them in a visually compelling way, making data more accessible to decision-makers.
- Personalized Data DashboardsAI can tailor data visualizations to individual user needs and preferences, providing customized insights and recommendations.
- Predictive AnalyticsAI can be used to build predictive models that forecast future trends and behaviors based on historical data.
4. AI in Data Storage and Management
- Data LakehousesAI is being integrated into data lakehouses, which combine the flexibility of data lakes with the structure and performance of data warehouses, to support complex AI/ML workloads.
- Graph DatabasesGraph databases like Neo4j and Amazon Neptune are used to store and query complex relationships within data, particularly useful for AI applications that require understanding connections between entities.
5. AI in Specific Domains
- AI-powered Recommendation SystemsBuilding recommendation engines that suggest relevant products, content, or information based on user behavior and preferences.
- AI for Fraud DetectionDeveloping systems that detect fraudulent transactions in real-time using machine learning techniques.
- AI for Fake News DetectionUsing AI and NLP to identify and filter out fake news and misinformation.
- AI for Resume ParsingBuilding systems that can automatically extract information from resumes, such as skills, experience, and education.
6. Key Technologies and Frameworks
- Cloud Data Warehouses
Snowflake, Google BigQuery, Databricks Lakehouse. - Real-time Processing
Apache Kafka, Apache Flink, Materialize. - Workflow Orchestration
Apache Airflow, Dagster, Prefect, Flyte. - Machine Learning Frameworks
TensorFlow Extended (TFX), MLflow, AWS SageMaker, PyTorch. - Serverless Computing
AWS Lambda, Google Cloud Functions.
